Getting Started with Development
Note: This documentation is in-progress. Please comment with any specific suggestions or corrections by creating an issue here.
Better yet, start a pull request.
Installation
Follow the following directions for cloning the repository and installing requirements.
Prerequisites
- Git installed
- GitHub account
- Python 3.6, 3.7, or 3.8.
- Virtual environment manager (pipenv, virtualenv, virtualenv-wrapper, etc.). Pipenv is the most popular option here.
You can find more details on setting up these tools and other common issues in Setup Help.
Clone the Repository
- Fork the Pittsburgh City Scrapers repository
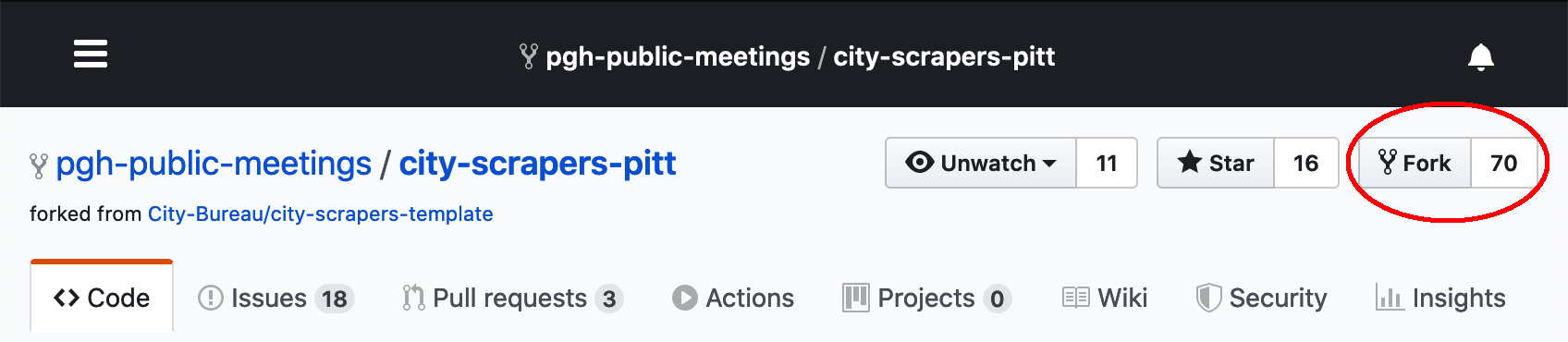
- Clone your new fork to your local machine:
git clone https://github.com/YOUR-USERNAME/city-scrapers-pitt.git
- Change directories into the main project folder:
cd city-scrapers-pitt
pipenv installation
pipenv is package management tool for Python which combines managing dependencies and virtual environments. It’s also designed to be compatible with Windows. Without a tool like pipenv you would have to spend time manually updating all of the packages and dependencies to make sure that your code will pass in our testing environment.
To setup an environment with pipenv, run:
pipenv sync --dev --three
The “dev” flag here means to install both develop and default packages, and the “three” flag means use Python 3 when creating virtualenv.
Then, you can either activate the virtual environment similarly to tools like virtualenv-wrapper by running:
pipenv shell
After which all of your commands will be in a virtual environment. You can exit this environment by running exit, or by entering CTRL+D.
When inside the virtual environment your prompt will resemble
(city-scrapers-pitt)$
Now you can list the available spiders with
(city-scrapers-pitt)$ scrapy list
and see output similar to this:
alle_airport
alle_asset_district
alle_county
alle_health
alle_improvements
pa_dept_environmental_protection
pa_development
pa_liquorboard
pa_utility
pgh_mayor_office_comm_aff
pgh_public_schools
pitt_art_commission
pitt_city_council
pitt_city_planning
pitt_housing_opp
pitt_urbandev
Next, we can run any of the spiders in the list. For example:
(city-scrapers-pitt)$ scrapy crawl pa_development
The results will contain JSON objects describing a list of meetings for the Pennsylvania Department of Community and Economic Development, along with debug output from scrapy. Here is a basic example of what one of the meeting JSON records looks like. Your local run of scrapy might not return this exact record, as it depends on the current status of the website. Note that your output will include other data as well such as scrapy debug messages.
{'all_day': False,
'classification': 'Board',
'description': '',
'end': datetime.datetime(2020, 4, 23, 14, 0),
'id': 'pa_development/202004231000/x/bftda_board_meeting',
'links': [{'href': '', 'title': ''}],
'location': {'address': '400 North Street, Harrisburg, PA, 17120',
'name': 'KBMC – Desert Room, First Floor, Commonwealth Keystone '
'Building'},
'source': 'https://dced.pa.gov/event/bftda-board-meeting-2020-04-23/',
'start': datetime.datetime(2020, 4, 23, 10, 0),
'status': 'tentative',
'time_notes': '',
'title': 'BFTDA Board Meeting'}
Congratulations - this means that Scrapy is working and we are ready to contribute!
If you’re having any issues at this point, here are some options:
- Talk to other contributors on Slack or at our Meetups. It’s very likely that someone else has encountered your situation before and can quickly point you in the right direction.
- See if your problem shows up in our issues page.
- Googling the error message
- StackOverflow
{kind=link}
Contribute
Ways to Contribute
There are many ways to contribute to this project: coding a spider (webscraper), building infrastructure, improving documentation, hosting in-person code evenings, and participating in technical discussions in Slack about code and design choices. Request an invite to our Slack by filling out this form.
Familiarize Yourself with how we work
The best way to familiarize yourself with the code base is to build a spider. Follow the installation and contributing-a-spider sections below to get started. Reach out on Slack for support. Familiarize yourself with how we workPermalink
Please read the project’s CONTRIBUTING.md file to learn about how we use GitHub to manage the project and our pull request policy.
Spider Setup
- Find an open issue to work on:
First, find an issue within the project’s issue tracker. If the issue does not have a pull request and has no one working on it, go ahead and leave a comment to the effect of “I’m working on this”. If someone has been working on the spider, but it has been more than 3-4 months since they updated anything, feel free to continue their work on that spider or start your own solution.
As an example we will use the Urban Redevelopment Authority of Pittsburgh, or URA for short. It has an issue. Someone started work on it but appears to have moved on to other commitments. I’ll leave a comment and proceed to step 2.
- Create a new branch Before leaving the master branch, sync your fork to the project’s repository. This will save time later on when trying to add your spider to the project. To do this run:
git remote add upstream https://github.com/pgh-public-meetings/city-scrapers-pitt.git
git fetch upstream
git merge upstream/master
Now that we’re all in sync, create a new branch in your fork:
git checkout -b NAMEOFAGENCY-spider
XXX is the zero-padded issue number and NAMEOFAGENCY should be something like alle_county.
For the URA, I would use 0005 as my issue number and pitt_urbandev as NAMEOFAGENCY as follows:
git checkout -b 0005-spider-pitt_urbandev
Now when we run ‘git branch’ we will see
$ git branch
* 0005-spider-pitt_urbandev
master
We have a branch! Move on to step 3.
3. Create a spider
Create a spider from our template with a spider slug, agency name, and a URL to start scraping. Inside your virtual environment following the previous examples (or prefixed by pipenv run) run:
scrapy genspider pitt_urbandev "Urban Redevelopment Authority of Pittsburgh" https://www.ura.org/pages/board-meeting-notices-agendas-and-minutes
You should see some output like:
Created file: /Users/ben/Desktop/documentation/example/city-scrapers-pitt/tests/files/pitt_urbandev.html
Created file: /Users/ben/Desktop/documentation/example/city-scrapers-pitt/city_scrapers/spiders/pitt_urbandev.py
Created file: /Users/ben/Desktop/documentation/example/city-scrapers-pitt/tests/test_pitt_urbandev.py
Now you have a bare-bones spider! Move on to step 4.
4. Test crawling
You now have a spider named pitt_urbandev. To run it (admittedly, not much will happen until you start editing the scraper), run:
(city-scrapers-pitt)$ scrapy crawl pitt_urbandev
If there are no error messages, congratulations! Move on to step 5.
5. Run the automated tests
We use the pytest testing framework to verify the behavior of the project’s code. To run this, simply run pytest in your project environment.
(city-scrapers-pitt)$ pytest
Whoops! The tests for new spiders fail by default. Here’s typical output:
(city-scrapers-pitt)$ pytest
==================================================================== test session starts ====================================================================
platform darwin -- Python 3.7.5, pytest-5.3.2, py-1.8.1, pluggy-0.13.1
rootdir: /Users/ben/Desktop/documentation/example/city-scrapers-pitt, inifile: setup.cfg
collected 214 items
tests/test_alle_airport.py ......... [ 4%]
tests/test_alle_county.py ............. [ 10%]
tests/test_alle_health.py .. [ 11%]
tests/test_alle_improvements.py ..................... [ 21%]
tests/test_alle_port_authority.py ...................... [ 31%]
tests/test_pa_dept_environmental_protection.py ........ [ 35%]
tests/test_pa_development.py ............................................... [ 57%]
tests/test_pa_liquorboard.py . [ 57%]
tests/test_pgh_mayor_office_comm_aff.py . [ 57%]
tests/test_pgh_public_schools.py . [ 58%]
tests/test_pitt_art_commission.py .......... [ 63%]
tests/test_pitt_city_council.py ........................................................... [ 90%]
tests/test_pitt_city_planning.py ....... [ 93%]
tests/test_pitt_housing_opp.py ............ [ 99%]
tests/test_pitt_urbandev.py F [100%]
========================================================================= FAILURES ==========================================================================
________________________________________________________________________ test_tests _________________________________________________________________________
def test_tests():
print("Please write some tests for this spider or at least disable this one.")
> assert False
E assert False
tests/test_pitt_urbandev.py:27: AssertionError
------------------------------------------------------------------- Captured stdout call --------------------------------------------------------------------
Please write some tests for this spider or at least disable this one.
=============================================================== 1 failed, 213 passed in 2.68s ===============================================================
(city-scrapers-pitt)$
This is normal since you have not written any tests for your new spider and the assertion assert False will always fail. Move on to step 6.
6. Run linting and style-checking tools
We use black to check that all code is written in the proper style. To run these tools individually, you can run the following commands:
(city-scrapers-pitt)$ black .
Some of these tests might not pass right now, but they should before you are finished with the spider.
Run these commands early and often! They will help you learn the language and style, discover bugs sooner, and avoid the nasty experience of having to fix dozens of style complaints all at once.
Good news! If you’re lazy like us, most text editors can be configured to fix style issues for you based off of the configuration settings in setup.cfg. See an example of this for VSCode in Setup Help.
Building a spider
A. Write parse methods in the spider
Open city_scrapers/spiders/pitt_urbandev.py to work on your spider. A simple structure has been created for you to use. Let’s look at the basics.
The spider should look something like this:
from city_scrapers_core.constants import NOT_CLASSIFIED
from city_scrapers_core.items import Meeting
from city_scrapers_core.spiders import CityScrapersSpider
class PittUrbandevSpider(CityScrapersSpider):
name = "pitt_urbandev"
agency = "Urban Redevelopment Authority of Pittsburgh"
timezone = "America/Chicago"
start_urls = ["https://www.ura.org/pages/board-meeting-notices-agendas-and-minutes"]
def parse(self, response):
"""
`parse` should always `yield` Meeting items.
Change the `_parse_title`, `_parse_start`, etc methods to fit your scraping
needs.
"""
for item in response.css(".meetings"):
meeting = Meeting(
title=self._parse_title(item),
description=self._parse_description(item),
classification=self._parse_classification(item),
start=self._parse_start(item),
end=self._parse_end(item),
all_day=self._parse_all_day(item),
time_notes=self._parse_time_notes(item),
location=self._parse_location(item),
links=self._parse_links(item),
source=self._parse_source(response),
)
meeting["status"] = self._get_status(meeting)
meeting["id"] = self._get_id(meeting)
yield meeting
def _parse_title(self, item):
"""Parse or generate meeting title."""
return ""
def _parse_description(self, item):
"""Parse or generate meeting description."""
return ""
def _parse_classification(self, item):
"""Parse or generate classification from allowed options."""
return NOT_CLASSIFIED
# ...
Every spider inherits from our custom CityScrapersSpider class, defined in the city_scrapers_core package which provides some of the helper functions like _get_id and _get_status. Each spider should yield Meeting items in the parse method (or another helper method depending on the page). See a more detailed description of Meeting items below.
There are pre-defined values for things like the spider’s name, agency, etc. Check that these all make sense. For example, for Eastern Standard Time we would want to change the timezone from "America/Chicago" to "America/New_York".
There also are pre-defined helper methods for every major field in the data. It’s your job to fill them in.
For example, _parse_title could be filled in as:
TITLE = "URA Board Meeting" # This is a constant
class PittUrbandevSpider(Spider):
# ...
def _parse_title(self, item):
"""Parse or generate meeting title."""
# In this situation, the title did not change from one
# meeting to the next, so we simply return a constant string:
return TITLE
# ...
Often a value for meetings returned by a spider will be the same regardless of meeting content. For example, most meetings will always have False for the all_day value. For fields like classification, all_day, and title (sometimes), feel free to remove the _parse_* method for that field, and simply include the value in each dictionary (so 'all_day': False in this example rather than 'all_day': self._parse_all_day(item)).
So we could refactor our previous example as:
TITLE = "URA Board Meeting" # This is a constant
class PittUrbandevSpider(Spider):
# ...
def parse(self, response):
# ...
for item in response.css(".meetings"):
meeting = Meeting(
title=TITLE,
# ...
)
Caveat: Scheduling details like time and location should be pulled from the page, even if the value is always the same. In some cases it can be easier to make sure that an expected value is there and raise an error if not than to parse it every time. An example of raising an error if information has changed can be found in chi_license_appeal
B. Write tests
How can we write better code, refactor with confidence, and document precisely how your spider was intended to behave? Tests.
Our general approach to writing tests is to save a copy of a site’s HTML in tests/files and then use that HTML to verify the behavior of each spider. By saving a copy we avoid needing a network connection to run tests, and our tests don’t break every time a site’s content is updated.
This is a great opportunity to practice test-driven-development:
- write a “single” unit test describing an aspect of the program
- run the test, which should fail because the program lacks that feature
- write “just enough” code, the simplest possible, to make the test pass
- “refactor” the code until it conforms to the simplicity criteria
- repeat, “accumulating” unit tests over time
Here is the test setup and an example test:
...
# Load the copy of the site's HTML response.
test_response = file_response(
join(dirname(__file__), "files", "pitt_urbandev.html"),
url="https://www.ura.org/pages/board-meeting-notices-agendas-and-minutes",
)
# Instantiate a spider.
spider = PittUrbandevSpider()
# Freeze time.
freezer = freeze_time("2020-01-25")
freezer.start()
# Get the events .
parsed_items = [item for item in spider.parse(test_response)]
# Test that the description of the first event is right.
def test_description():
assert parsed_items[0]["description"] == "Rescheduled board meeting"
...
You’ll notice that the freeze_time function is called from the freezegun library before items are parsed from the spider. This is because some of our functions, _get_status in particular, are time-sensitive and their outputs will change depending when they’re executed. Calling freeze_time with the date the test HTML was initially scraped ensures that we will get the same output in our tests no matter when we run them.
You generally want to verify that a spider:
- Extracts the correct number of events from a page.
- Extracts the correct values from a single event.
- Parses any date and time values, combining them as needed.
C. Create a Pull Request
If you are ready to submit your code to the project, you should create a pull request on GitHub. You can do this as early as you would like in order to get feedback from others working on the project.
When you go to open a pull request, you’ll see a template with details pre-populated including a checklist of tasks to complete. Fill out the information as best you can (it’s alright if you can’t check everything off yet). It’s designed to provide some reminders for tasks to complete as well as making review easier. You can use the rest of the description to explain anything you’d like a reviewer to know about the code. See CONTRIBUTING.md for more details.
Meeting Items
The Meeting items you need to return are derived from Scrapy’s Item classes. The original source can be found in the city_scrapers_core package.
A Scrapy Item mostly functions like a normal Python dict. You can create a Meeting Item with Python keyword arguments and also set values after it’s created with Python’s general dict syntax:
meeting = Meeting(
title='Board of Directors',
description='',
) # This creates a Meeting
meeting['source'] = 'https://example.com' # This sets a value on the Meeting
Each of the values in Meeting should adhere to some guidelines.
id
Unique identifier for a meeting created from the scraped its scraped details. This should almost always be populated by the _get_id method inherited from CityScrapersSpider and not set directly.
title
The title of an individual instance of a meeting. Because most of the meetings we’re scraping occur on a regular basis, sometimes this is alright to set statically if we can be reasonably certain that it won’t change. Some common examples are “Board of Directors” or “Finance Committee”.
description
A string describing the specific meeting (not the overall agency). This usually isn’t available, and in that case it should default to an empty string.
classification
One of the allowed classification constants describing the type of the meeting.
status
One of the allowed status constants describing the meeting’s current status. Generally you shouldn’t edit this other than to set it with the _get_status method which checks the meeting title and description for any indication of a cancellation. If there is relevant text in a meeting’s description (like “CANCELLED” displaying next to the meeting name outside of the title) you can pass it to the _get_status method as a keyword argument like this:
meeting["status"] = self._get_status(item, text="Meeting is cancelled")
start
Naive datetime object indicating the date and time a meeting will start. The agency’s timezone (from the spider’s timezone property) will be applied in the pipelines, so that doesn’t need to be managed in the spider. All spiders should have a value for start, and if a time is unavailable and there are no sensible defaults it should be listed as 12:00 am.
end
Naive datetime or None indicating the date and time a meeting will end. This is most often not available, but otherwise the same rules apply to it as start.
all_day
Boolean indicating whether or not the meeting occurs all day. It’s mostly a carryover from the Open Civic Data event specification, and is almost always set to False.
time_notes
String indicating anything people should know about the meeting’s time. This can be anything from indicating that a meeting will start immediately following the previous one (so the time might not be accurate) or a general indication to double-check the time if the agency suggests that attendees should confirm in advance.
location
Dictionary with required name and address strings indicating where the meeting will take place. Either or both values can be empty strings, but if no location is available either a default should be found (most meetings have usual locations) or TBD should be listed as the name. If a meeting has a standing location that is listed separate from individual meetings, creating a _validate_location that checks whether the meeting location has changed (and returns an error if it has) can be sometimes be more straightforward than trying to parse the same location each time.
{
"name": "City Hall",
"address": "1234 Fake St, Chicago, IL 60601"
}
links
A list of dictionaries including values title and href for any relevant links like agendas, minutes or other materials. The href property should always return the full URL and not relative paths like /doc.pdf.
source
The URL the meeting was scraped from, which will almost always be response.url with the exception of scraping some lists with detail pages.
Since we’re aggregating a wide variety of different types of meetings and information into a single schema, there are bound to be cases where the categories are unclear or don’t seem to fit. Don’t hesitate to reach out in a GitHub issue or on Slack if you aren’t sure where certain information should go.
Constants
When setting values for classification or status (although status should generally be set with the _get_status method), you should import values from city_scrapers_core.constants. These constants are defined to avoid accidental mistakes like inconsistent capitalization or spelling for values that have a predefined list of options.
Classifications
ADVISORY_COMMITTEE: Advisory Committees or Councils (often Citizen’s Advisory Committees)BOARD: Boards of Trustees, Directors, etc.CITY_COUNCIL: Legislative branch of a local governmentCOMMISSION: Any agency with “commission” in the nameCOMMITTEE: Committees of larger agenciesFORUM: Public hearings, community input meetings, informational meetings etc.POLICE_BEAT: Specifically used for police beat meetingsNOT_CLASSIFIED: Anything that doesn’t seem to fit well into any of the prior categories
Statuses
CANCELLEDTENTATIVECONFIRMEDPASSED
Spider attributes
In addition, each spider records the following data as attributes:
class PittUrbandevSpider(CityScrapersSpider):
# name of spider in lowercase
name = "pitt_urbandev"
# name of agency
agency = "Urban Redevelopment Authority of Pittsburgh"
# timezone of the events in tzinfo format
timezone = "America/New_York"
agency
The agency name initially supplied on creating the spider should be the overall governmental body that spider relates to, even if the body is already represented in another scraper. An example of this is in the chi_schools, chi_school_actions, and chi_school_community_action_council spiders. All of these spiders relate to different subdivisions of Chicago Public Schools, but they’re split into separate spiders because they scrape different websites. In situations like this, the meeting name should clarify the subdivision holding the actual meeting, specifying the respective school actions and community action councils in this case.